Ich trau mich gar nicht es endgültig aufzulösen (weil ich noch nicht genug Uptime habe, um 1000% sicher zu sein

) ...es war doch ein Hitzeproblem. Darauf gekommen bin ich, weil ich hier in meiner Wohnung seit letzter Woche dahinschmelze und ich die zweite Maschine im großen Servertower nicht gecrasht bekam, weder idle noch unter Last. (später fiel mir noch auf, dass die Threads in anderen Foren mit meinen ähnlichen Problemen und Kernelpanics oft in den Monaten Juni/Juli herum waren

)
Das Sorgenkind 2HE Rack crashte allerdings in letzter Zeit nur noch idle.
Da ich ganz am Anfang schon bemerkte, dass die Kühlkörper brutal heiß werden und geraten wird, die Kühlkörper von den Stockwärmeleitpads zu befreien, mit neuer Paste zu beschmieren und noch einen Lüfter draufzuschnallen, hab ich das mal befolgt. Ich habe dazu einen Noctua NF-A4x20 bestellt und noch ein paar NF-A4x10 (zum Experimentieren), falls ersterer doch zu dick sein sollte und ich mir den benachbarten PCI-E Steckplatz zubauen sollte. Jedenfalls passte der dickere problemlos drauf und den habe ich jeweils immer auf die jeweilige Karte montiert, wenn ich im 2HE ebensolche zum Testen ausgewechselt hatte, weil 2HE einfach nicht viel Luft zum Atmen bietet. Das Kabel war exakt lang genug für den "REAR_FAN2" Anschluss vom Board. Jetzt der Clou: der NF-A4x20 hat 4pins zur dynamischen Lüftersteuerung, die kleineren NF-A4x10 nur 3pins. Im Eifer des Gefechts hab ich damals beim Bestellen nicht darauf geachtet, Noctua hat bei den Modellbezeichnungen die Zusätze 'PWM' für 4pins und 'FLX' für 3. Ein aktiviertes 'Auto Fan Control' mit Duty-Cycle 30% im BIOS trat dann immer die Fehlerkette in Gang. Ich dachte, dass das nur für den CPU-Fan gilt, aber nein, ist auch im Handbuch so nicht beschrieben. Alle Fananschlüsse orientieren sich anscheinend an der CPU-Temperatur (oder vllt. noch CPU0 MOS Area oder SR5670 Temp, konnte ich nicht rausfinden). Dh. unter Last ging die CPU-Temperatur (schnell genug) hoch und der CPU-Lüfter bis 7000rpm, das hat dann auch den Noctua auf seine maximalen 5000rpms hochgezogen.
Dadurch erklären sich auch alle meine Fehler...CPU ist idle, hat 26°, der Lüfter am Controller dreht deswegen nur mit 2000rpms und da kocht der Chip wahrscheinlich bereits an seiner Grenze (in Datenblättern fand ich 55° und auch 110°, was jetzt für den jeweiligen Chip stimmt oder ob Celsius oder Fahrenheit, weiß ich nicht. Jedenfalls habe ich im Netz keine Angabe gefunden, wie man die Temperatur auslesen könnte. Bilde mir aber ein, dass ich bei den ganzen DOS-Tools megarec, sas2flsh zum Flashen mal 'ROC Temperature' über den Screen huschen sah. Weiß da wer genaueres?).
So...und kommt dann nachts mal ein 'periodic daily' daher oder streame ich ein video, langweilt sich die CPU so gähnig, dass beide Lüfter nicht hochgezogen werden, aber der HBA steigt dann irgendwann aus. Dh. es war immer pures Glück, dass während meiner Woche Urlaub oder den Wochenenden die Temperatur gerade so unter Limit beim periodic daily blieb.
Ich hab den 4pin Noctua jetzt stumpf an die Backplane angeschlossen, da gibts nur 3pins, der CPU-Fan soll ja weiterhin dynamisch laufen. Im Tower-Server hab ich den kleinen NF-A4x10 auf dem SAS2008 am 'REAR_FAN2', das klappt, weil der eh nur 3pins hat und stiefelt fest mit 4800rpms, was ich per IPMI auslesen kann.
Heureka!
Da das nun geschafft war, hab ich auch die Firmware 20.00.07.00 nochmal ausprobiert und mittels mpsutil im live-Betrieb geflasht. Ich hab mir nichtmal die Mühe gemacht, den pool auszuhängen. Wenn man sich routiniert fühlt und Backups hat, wird man mutig.
")
Sofern der Controller bereits crossflashed ist, also LSI Firmware und die SAS-Adresse hat, stiefelt das einwandfrei durch mit ein paar Sekunden. Zum Reinitialisieren hab ich die ganze Kiste dann neu gestartet, hat geklappt. Also Firmware 20.00.07.00 mit Driver: 21.02.00.00-fbsd stiefelt jetzt einwandfrei auf dem SAS2308 und beiden SAS2008.
Für google, falls wer darüber kommt. Da würde ich dann sagen, dass die allgemeine Meinung zutrifft, die man in den Foren zu den Firmwares liest:
-19.00.00.00 funktioniert
-20.00.00.00 - ??? -> murksig, soll wohl auch von LSI bestätigt sein
-20.00.04.00, 20.00.06.00, 20.00.07.00 funktioniert
Noch ne Frage an die Experten:
Da ich am ZFS bisher nichts rumgetunt hatte und erneut durch meine zfs send/receive Experimente, diese Kills (pid 817 (ntpd), uid 0, was killed: out of swap space) mit sshd, ntpd und div. anderen wichtigen Diensten hatte. Wie regelt man das und wieso ist das so? Da waren auf einen Schlag 10 Dienste gekillt worden. Per ssh kam ich dann wieder rein, flog aber dann gleich wieder nach ein paar Sekunden raus. Nur reboot half.
Wieso ist der Back-Pressure/ARC so träge? Ich mein, das ist ein 11.2-Release und frisch installiert, nichts verbastelt, nichts damit vorher gemacht. Mir ist klar, dass sich das einpendelt (steckt da sowas wie eine Lernroutine dahinter oder wird stumpf %-x vom RAM genommen?) und ein System, welches z.B. 60 Tage rumidlete dann unter ZFS-Last plötzlich umdenken muß. Nix gegen Verzögerungen, aber dass das System dann unbenutzbar wird, wenn der Fall eintritt, stell ich mir unschön vor, wenn die Maschine 500km entfernt stehen sollte.
Und überhaupt....wieso wird dann der swap nicht genutzt, damit das nicht passiert? Sollte in der Prioliste nicht zuerst swap kommen, bevor der oom-Killer zulangt?
Ich hab auf jeder Platte meine RAM-Größe als swap. Ist eigentlich Platzverschwendung, ich weiß...aber wieso wird der nicht zuerst verbraten?
Jetzt die allerwichtigste Frage:
ich hab in der loader.conf jetzt mal
reingeschrieben, neu gestartet, mit top und zfs-stats überprüft. Macht man das so oder ist das Pfusch mit dem Holzhammer oder fummelt man noch an den vm.kmem-Variablen rum?
Jedenfalls wurde bisher auf keiner der beiden Maschinen danach mehr ein Dienst beendet.


")

 bios1.webp47,8 KB · Aufrufe: 446
bios1.webp47,8 KB · Aufrufe: 446 bios2.webp64,3 KB · Aufrufe: 477
bios2.webp64,3 KB · Aufrufe: 477 IMG_20180725_115902.webp127,9 KB · Aufrufe: 394
IMG_20180725_115902.webp127,9 KB · Aufrufe: 394 IMG_20180725_120829.webp93,6 KB · Aufrufe: 406
IMG_20180725_120829.webp93,6 KB · Aufrufe: 406 IMG_20180725_120835.webp46,3 KB · Aufrufe: 433
IMG_20180725_120835.webp46,3 KB · Aufrufe: 433 IMG_20180725_120849.webp77,5 KB · Aufrufe: 427
IMG_20180725_120849.webp77,5 KB · Aufrufe: 427 IMG_20180725_120926.webp106,4 KB · Aufrufe: 443
IMG_20180725_120926.webp106,4 KB · Aufrufe: 443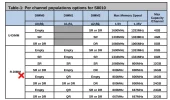 ramtabelle.webp67 KB · Aufrufe: 446
ramtabelle.webp67 KB · Aufrufe: 446 Screenshot_2018-07-25 TYAN® Computer - Motherboards S8010 S8010GM2NR - Support Lists.webp24,7 KB · Aufrufe: 437
Screenshot_2018-07-25 TYAN® Computer - Motherboards S8010 S8010GM2NR - Support Lists.webp24,7 KB · Aufrufe: 437
 )
)

