
gadean
Depp vom Dienst!
Hey,
ich könnte mal wieder eure Hilfe gebrauchen, nach dem ich dazu leider nichts brauchbares im Netz finden konnte.
Ich hab eine Kiste mit
Kurz zum Setup:
Die Kiste hat 4x HDD, darauf GELI und dann ZFS
Für die Netzfreigabe wird net/samba416 benutzt.
Jetzt habe ich zum zweiten mal (22. & 29.07.), eine Reihe von den Logs in
Jedes mal lief zu dem Zeitpunkt ein wöchentliches Backup, das ca. 600GB Daten von einem anderen Server (Proxmox-VE) via smb auf diese Kiste schreibt.
Meine Vermutung ist, das es irgendwie mit dem Schreibprozess des Backups (und/oder compression) zusammenhängt, da zu anderen Zeitpunkten teilst weit mehr Daten via smb auf die Kiste geschrieben werden und auch lokal erzeugt werden, ohne das die Meldungen auftauchen. Scrub läuft auch ohne Probleme durch.
S.M.A.R.T. Werte sehen unauffällig aus und die Steckverbindungen habe ich ebenfalls nochmal geprüft (die würde eher andere Fehler produzieren).
ich könnte mal wieder eure Hilfe gebrauchen, nach dem ich dazu leider nichts brauchbares im Netz finden konnte.
Ich hab eine Kiste mit
14.1-RELEASE welche aktuell unregelmäßig folgende Logs produziert:
Code:
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada1p1.eli[WRITE(offset=15233591767040, length=1028096)]
Jul 29 04:11:49 storage syslogd: last message repeated 3 times
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743460089856, length=1032192)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233591767040, length=1028096)]
Jul 29 04:11:49 storage syslogd: last message repeated 1 times
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada1p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage syslogd: last message repeated 11 times
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743462334464, length=995328)]
Jul 29 04:11:49 storage syslogd: last message repeated 1 times
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage syslogd: last message repeated 12 times
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada1p1.eli[WRITE(offsGEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233595748352, length=1032192)]
Jul 29 04:11:49 storage kernel: et=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offsGEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: et=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada3p1.eli[WRITE(offset=15233593749504, length=987136)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada2p1.eli[WRITE(offset=15743463329792, length=1048576)]
Jul 29 04:11:49 storage kernel: GEOM_ELI: Crypto request failed (ENOMEM). ada0p1.eli[WRITE(offset=15743463104512, length=1011712)]Kurz zum Setup:
Die Kiste hat 4x HDD, darauf GELI und dann ZFS
Für die Netzfreigabe wird net/samba416 benutzt.
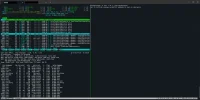
Code:
# zpool status
pool: zdata
state: ONLINE
scan: scrub repaired 0B in 21:53:21 with 0 errors on Wed Jul 24 01:49:16 2024
config:
NAME STATE READ WRITE CKSUM
zdata ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada3p1.eli ONLINE 0 0 0
ada1p1.eli ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada2p1.eli ONLINE 0 0 0
ada0p1.eli ONLINE 0 0 0
errors: No known data errors
Code:
# zfs get all zdata/backup | grep comp
zdata/backup compressratio 1.39x -
zdata/backup compression lz4 local
zdata/backup refcompressratio 1.56x -Jetzt habe ich zum zweiten mal (22. & 29.07.), eine Reihe von den Logs in
/var/log/messages vorgefunden und mir ist nicht ganz klar, was das bedeuten soll.Jedes mal lief zu dem Zeitpunkt ein wöchentliches Backup, das ca. 600GB Daten von einem anderen Server (Proxmox-VE) via smb auf diese Kiste schreibt.
Meine Vermutung ist, das es irgendwie mit dem Schreibprozess des Backups (und/oder compression) zusammenhängt, da zu anderen Zeitpunkten teilst weit mehr Daten via smb auf die Kiste geschrieben werden und auch lokal erzeugt werden, ohne das die Meldungen auftauchen. Scrub läuft auch ohne Probleme durch.
S.M.A.R.T. Werte sehen unauffällig aus und die Steckverbindungen habe ich ebenfalls nochmal geprüft (die würde eher andere Fehler produzieren).
")







")